Deploy a Audio Model
This document will help you on how to deploy a custom Audio Classification Model.
Before we start the deployment process, please follow the below formats for every file:
The model must contain the following pre-requisite files:
- requirement.txt - Text file containing for all your required packages along with the version.
scikit-learn==x.x.x
jsonify==x.x.x
matplotlib==x.x.x
librosa==x.x.x
pandas==x.x.x
resampy==x.x.x
- schema.py - This file will contain the type of input that will be excepted by your endpoint API. The template for the file is shown below.
from pydantic import BaseModel
from typing import List, Any
class PredictSchema(BaseModel):
data: List[List[Any]]
- launch.py - This is the most important file, containing loadmodel, preprocessing and prediction functions. The template for the file is shown below:
Note: loadmodel and prediction functions are compulsory. preprocessing function is optional based on the data you are passing to the system. By default false is returned from preprocessing function.
loadmodel takes logger object, please do not define your own logging object. preprocessing takes the data and logger object prediction takes preprocessed data, model and logger object.
from typing import Any, Dict
import pickle
import numpy as np
import tensorflow as tf
def loadmodel(logger):
"""Get model from cloud object storage."""
TRAINED_MODEL_FILEPATH = "audio_classification/"
logger.info(f"model path:{TRAINED_MODEL_FILEPATH}")
logger.info("loading model")
model = tf.keras.models.load_model(TRAINED_MODEL_FILEPATH)
labelencoder = ""
with open("labelencode.pickle", "rb") as f:
labelencoder = pickle.load(f)
logger.info("returning model object")
return [model, labelencoder]
def preprocessing(df: np.ndarray, logger):
"""Applies preprocessing techniques to the raw data"""
# Apply all preprocessing techniques inside this to your input data, if required
# then the return result will be other than False
logger.info("no preprocessing")
return False
def predict(features: np.ndarray, model: Any, logger) -> Dict[str, str]:
"""Predicts the results for the given inputs"""
try:
logger.info("model prediction")
audio_model, lbelencoder = model
predicted_label = audio_model.predict(features)
logger.info("prediction successful")
classes_x = np.argmax(predicted_label, axis=1)
prediction_class = lbelencoder.inverse_transform(classes_x)
logger.info("mapping the classes successful")
return prediction_class[0]
except Exception as e:
logger.info(e)
return e
Once you prepared the required files you can proceed with the deployment.
Note: Before Deployment the prepared required files should be inside the GitHub Repository.
How to deploy your audio model using Custom Deployment
1.Navigate to Deploy section from sidebar on the platform.
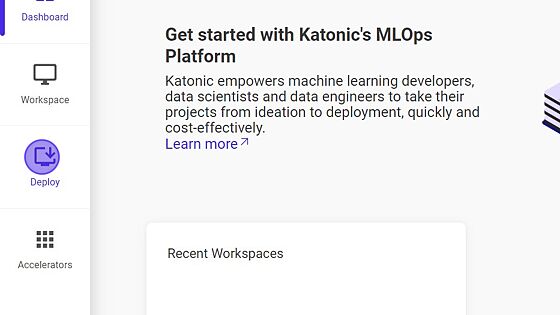
2.Select the Model Deployment option from the bottom.
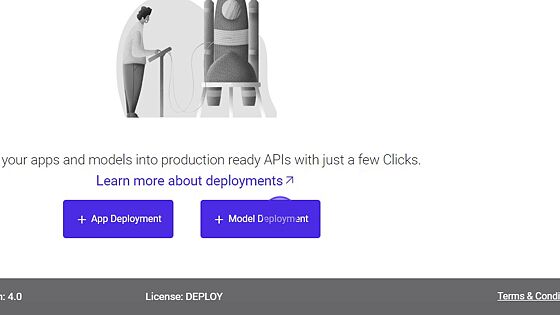
3.Fill the model details in the dialog box.
- Give a Name to your deployment, for example audio-to-speech and proceed to the next field.
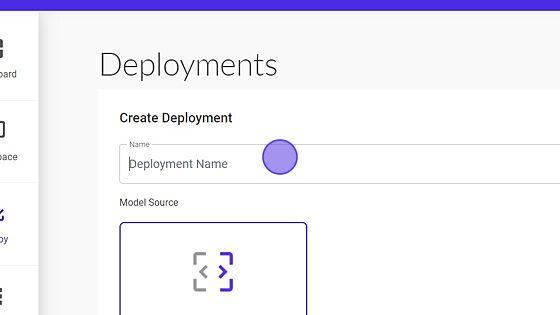
- Select Custom Model under Model Source option.
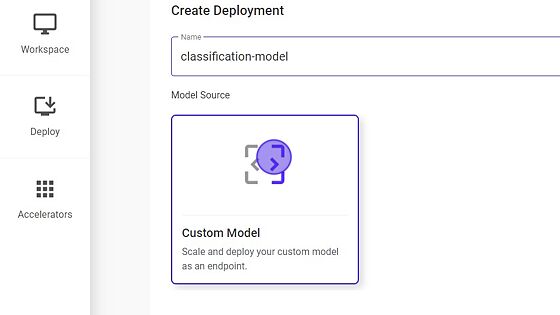
- Select Model type for eg., in this case it is Audio Classification.
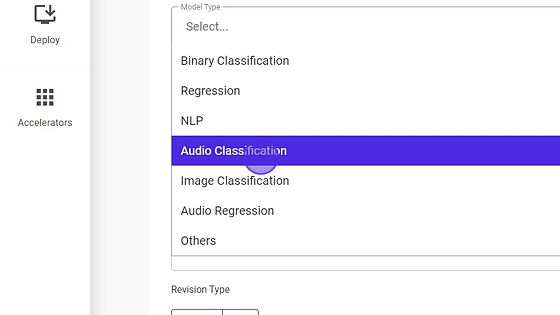
- Provide the GitHub token.
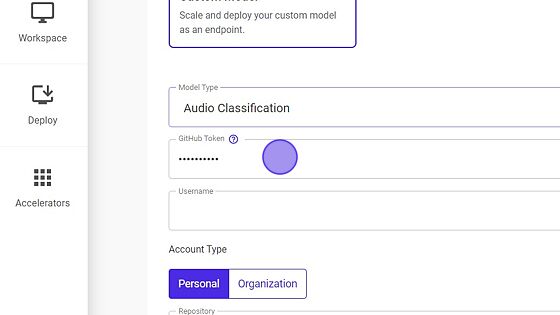
Your username will appear once the token is passed.
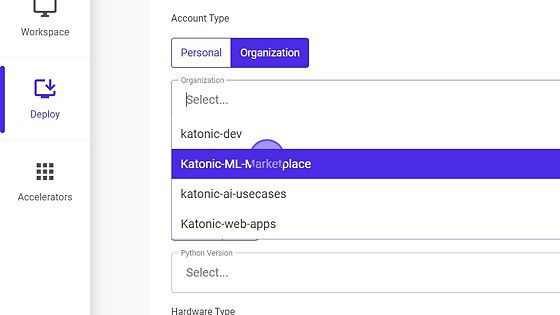
Select the Account type.
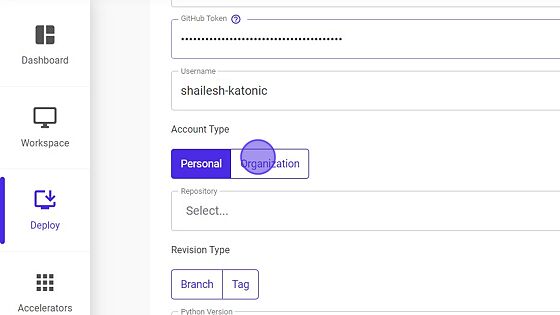
- Select Organization Name, if account type is
Organization.
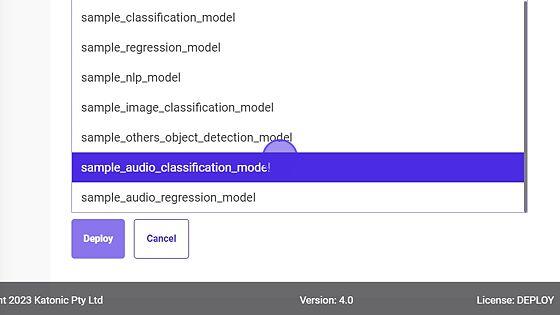
- Select the Repository.
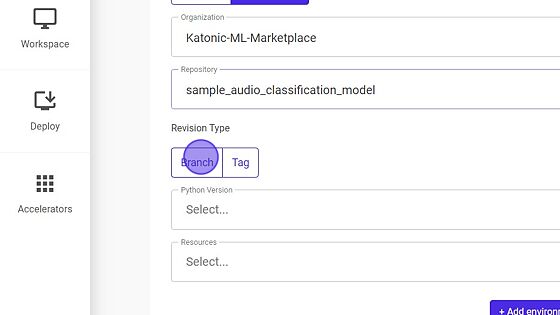
- Select the Revision Type.
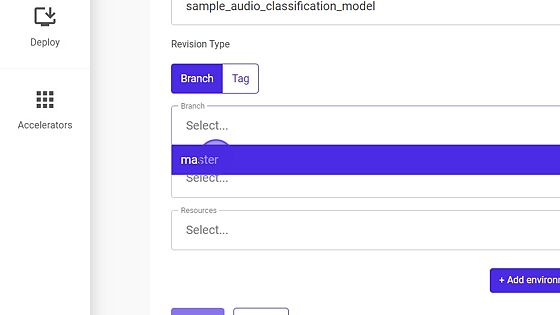
- Select the Branch Name, if revision type is
Branch.
Note: your GitHub repository must contain requirements.txt, schema.py and launch.py files whose templates are discussed above.
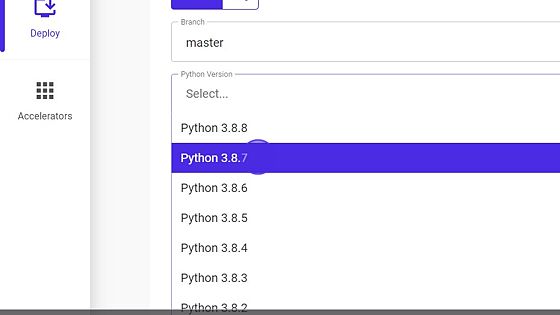
- Select Python version.
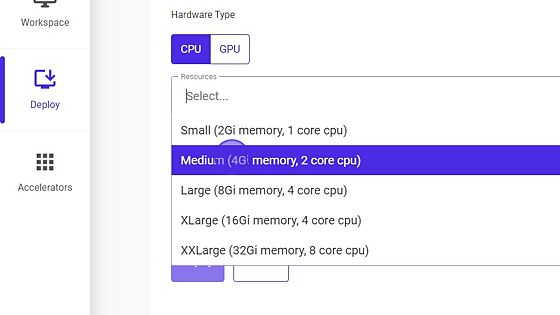
- Select Resources.
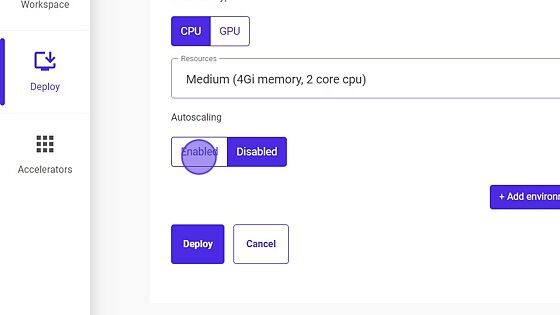
- Enable or Disable Autoscaling.
- Select Pods range if the user enable Autoscaling.
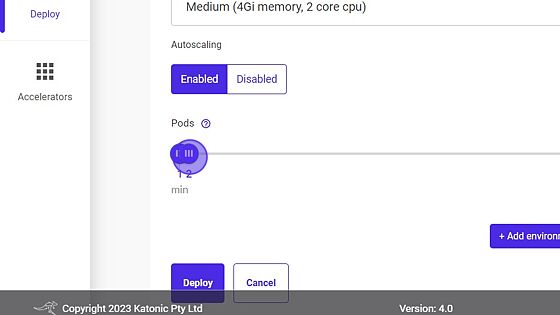
- Click on Deploy.

4.Once your Custom Model API is created you will be able to view it in the Deploy section where it will be in "Processing" state in the beginning. Click on Refresh to update the status.
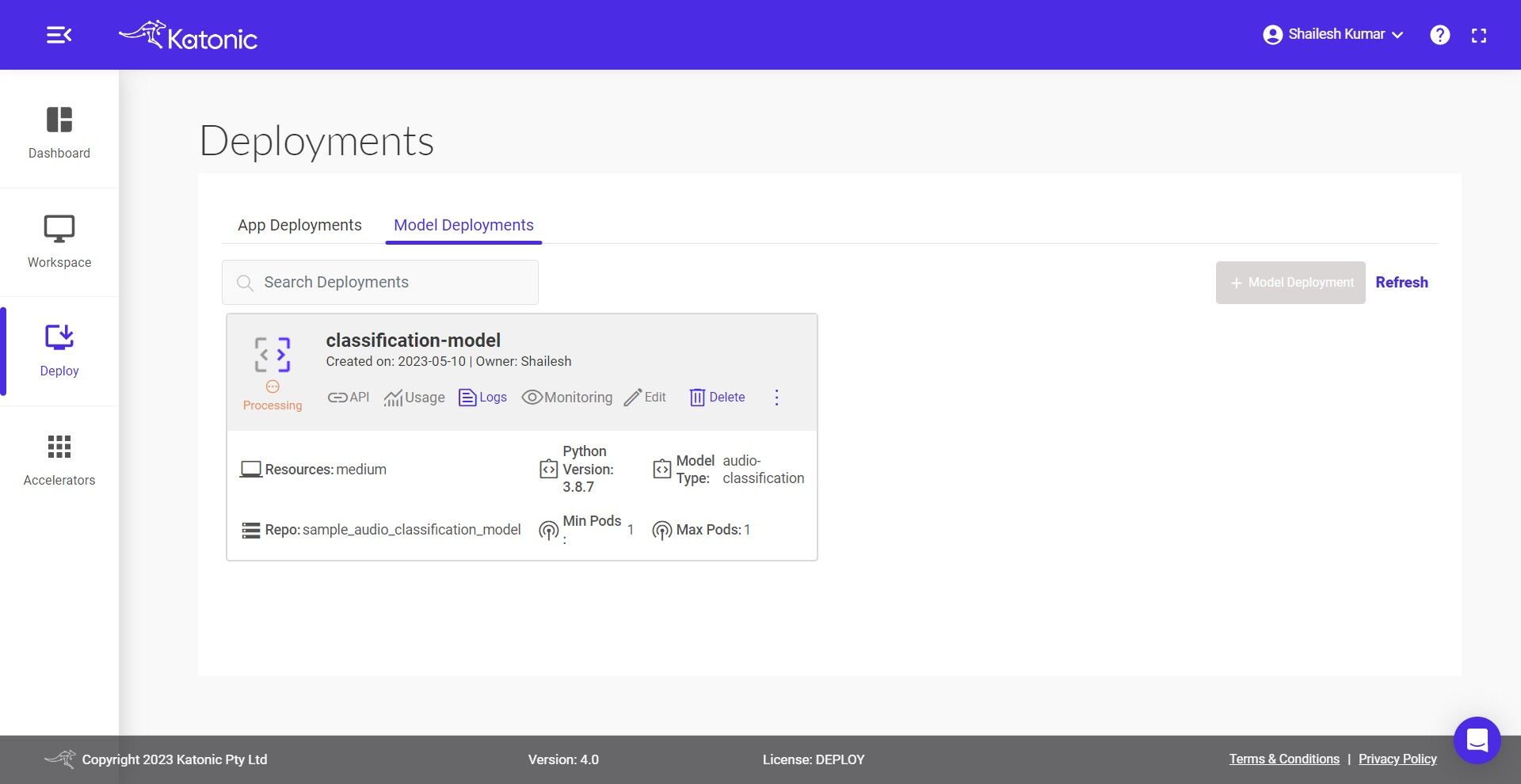
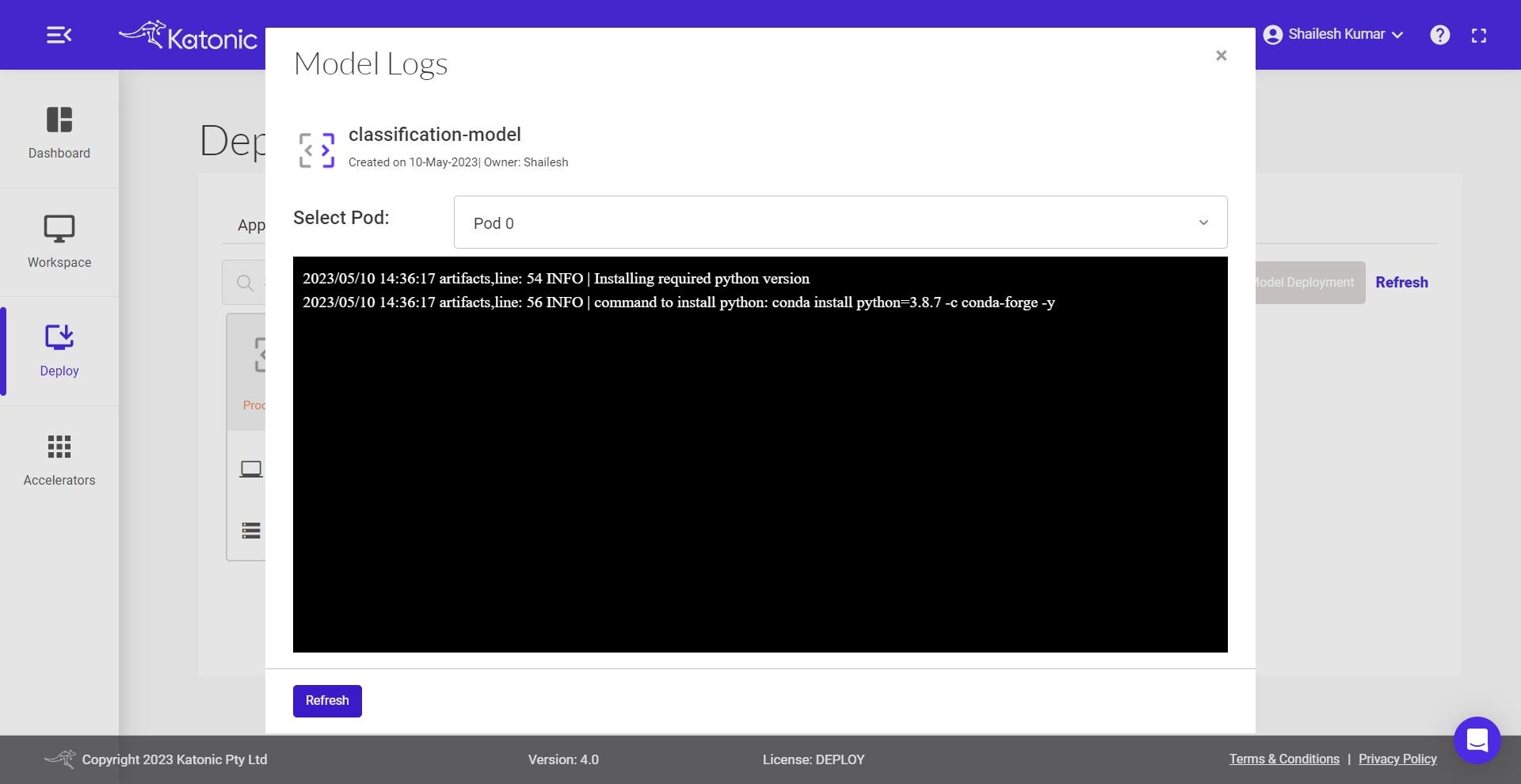
5.You can also check out the logs to see the progress of the current deployment using Logs option.
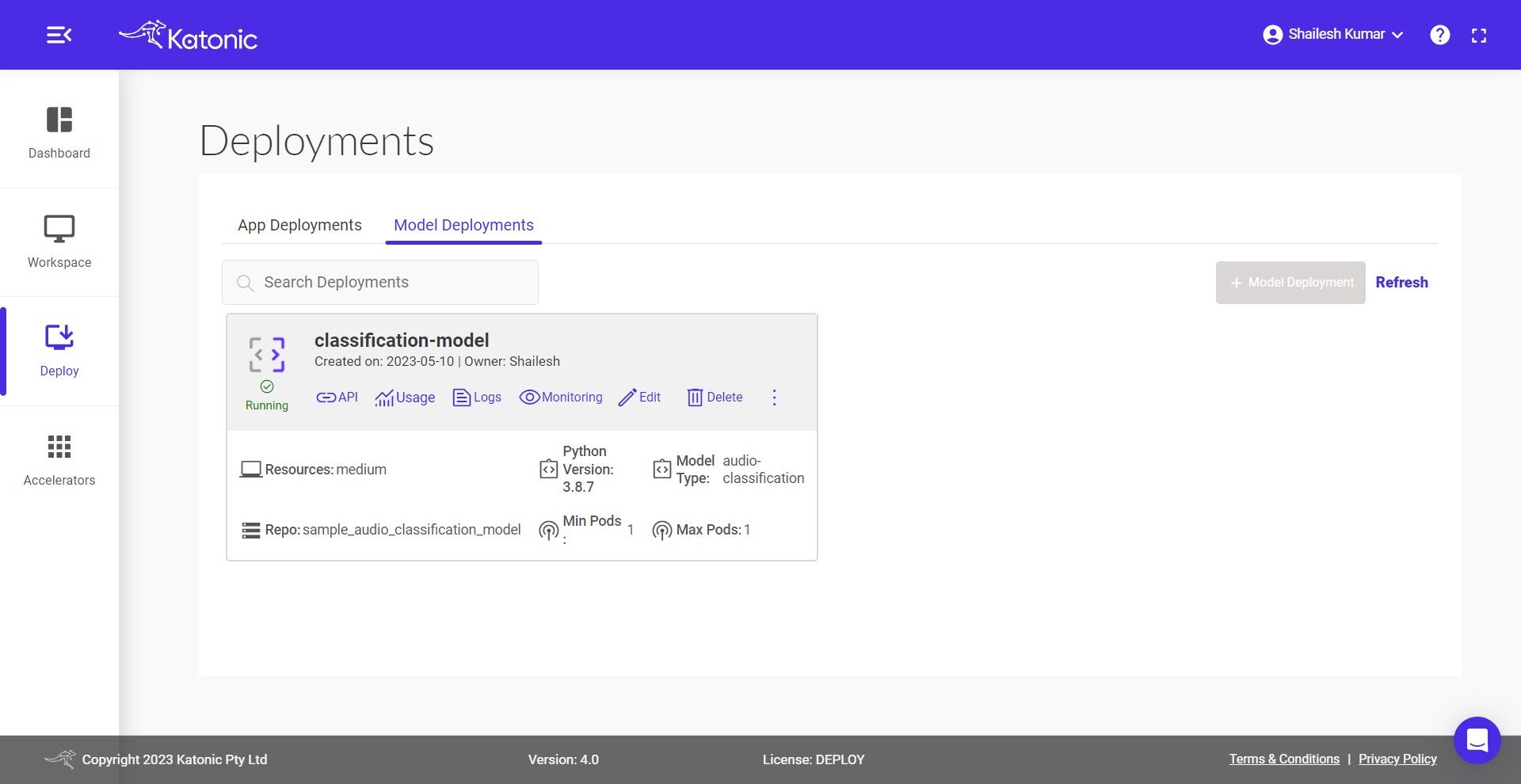
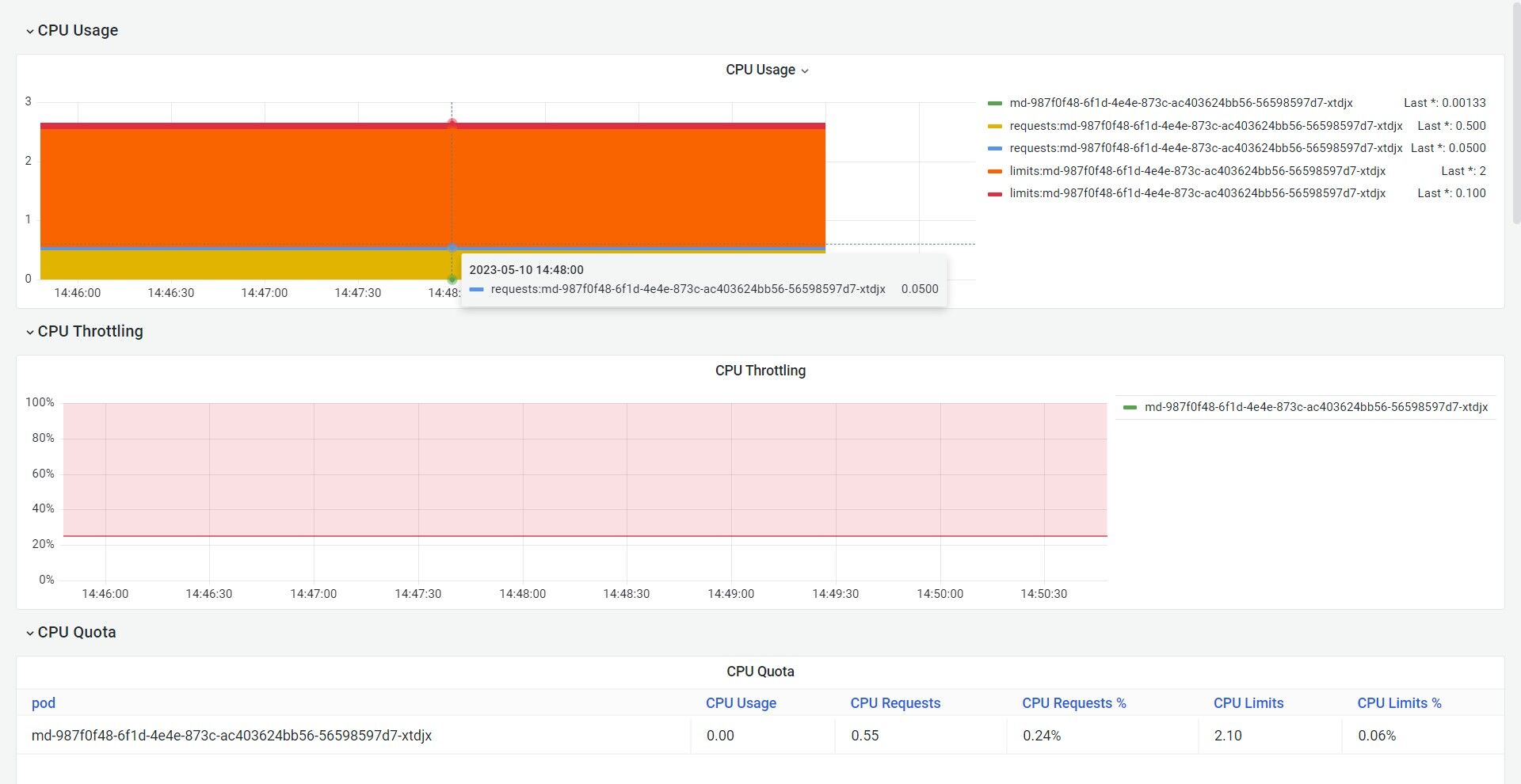
6.Once your Model API is in the Running state you can check consumption of the hardware resources from Usage option.
7.You can access the API endpoints by clicking on API.
There are two APIs under API URLs:
Model Prediction API endpoint: This API is for generating the prediction from the deployed model Here is the code snippet to use the predict API:
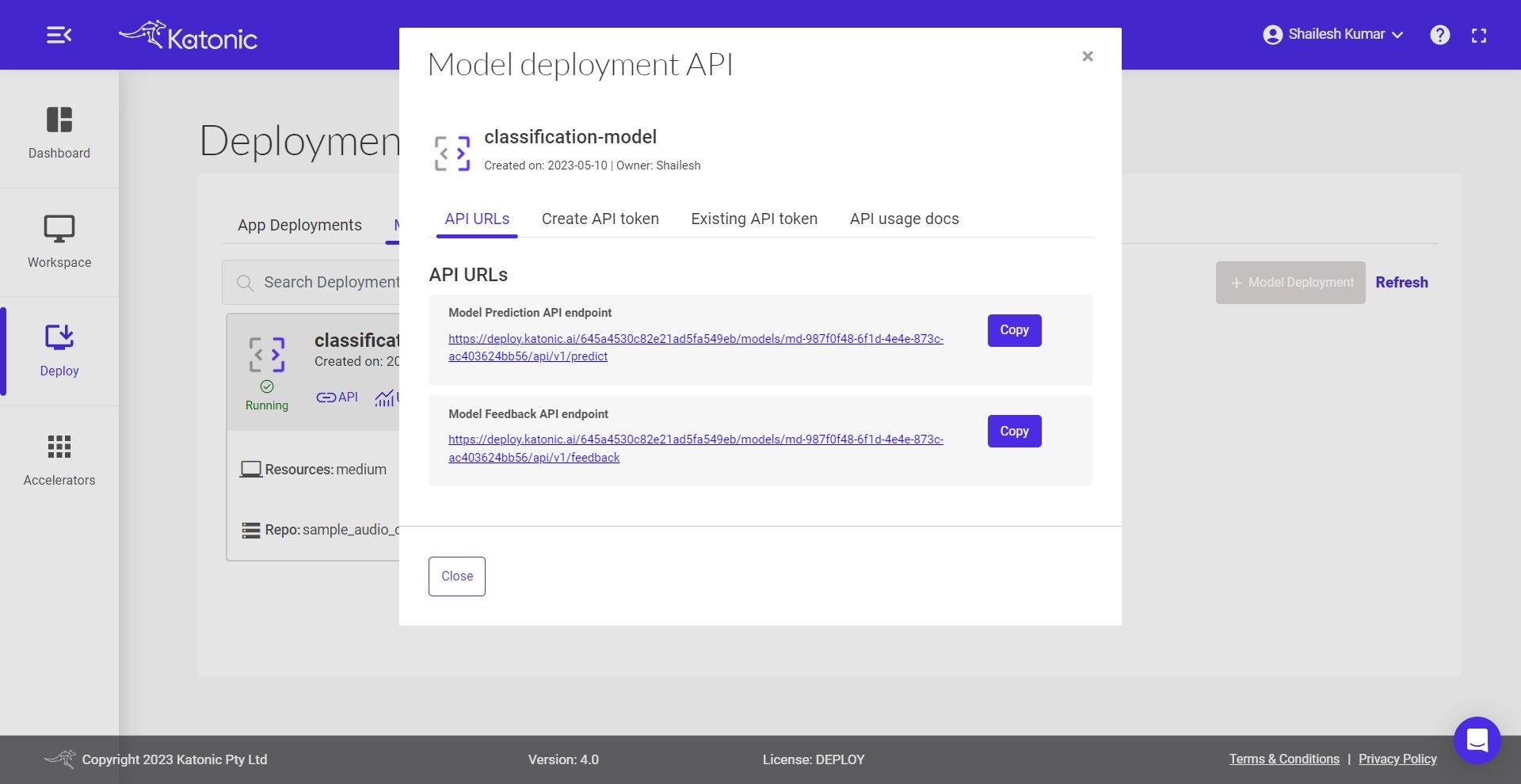
MODEL_API_ENDPOINT = "Prediction API URL"
SECURE_TOKEN = "Token"
data = {"data": "Define the value format as per the schema file"}
result = requests.post(f"{MODEL_API_ENDPOINT}", json=data, verify=False, headers = {"Authorization": SECURE_TOKEN})
print(result.text)
- Model Feedback API endpoint: This API is for monitoring the model performance once you have the true labels available for the data. Here is the code snippet to use the feedback API. The predicted labels can be saved at the destination sources and once the true labels are available those can be passed to the feedback url to monitor the model continuously.
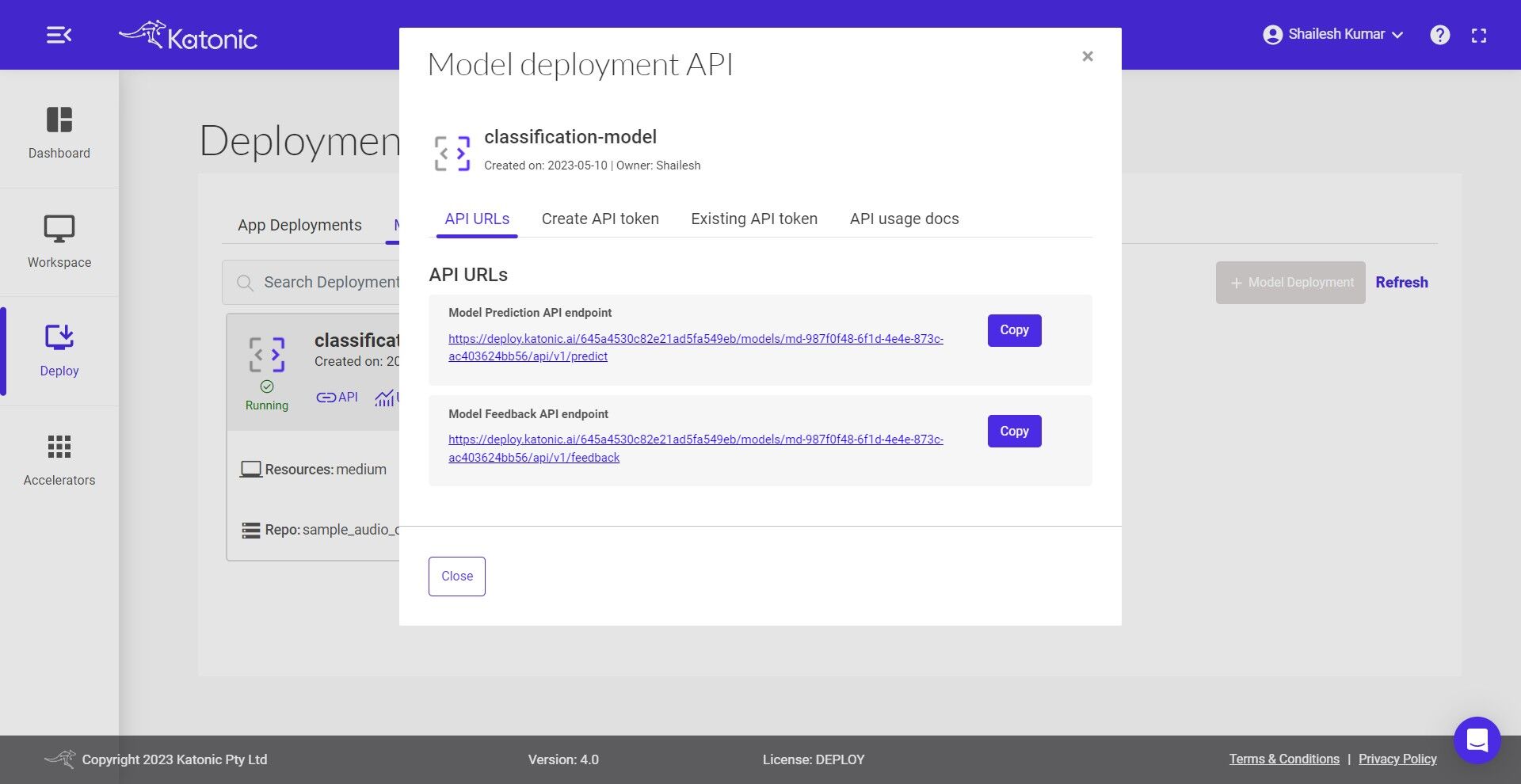
MODEL_FEEDBACK_ENDPOINT = "Feedback API URL"
SECURE_TOKEN = "Token"
true = "Pass the list of true labels"
pred = "Pass the list of predicted labels"
data = {"true_label": true, "predicted_label": pred}
result = requests.post(f"{MODEL_API_ENDPOINT}", json=data, verify=False, headers = {"Authorization": SECURE_TOKEN})
print(result.text)
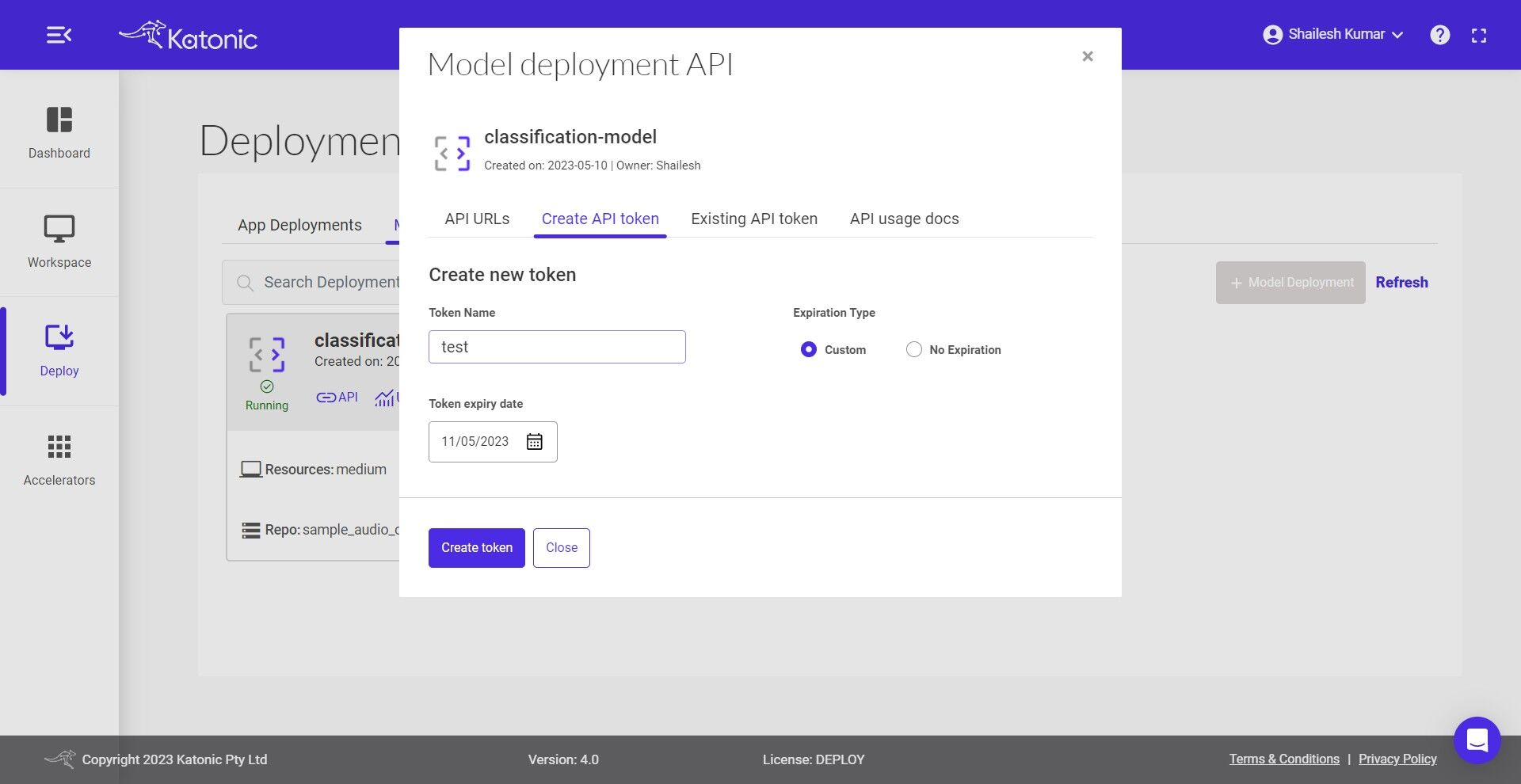
- Click on the Create API token to generate a new token in order to access the API.
- Give a name to the token.
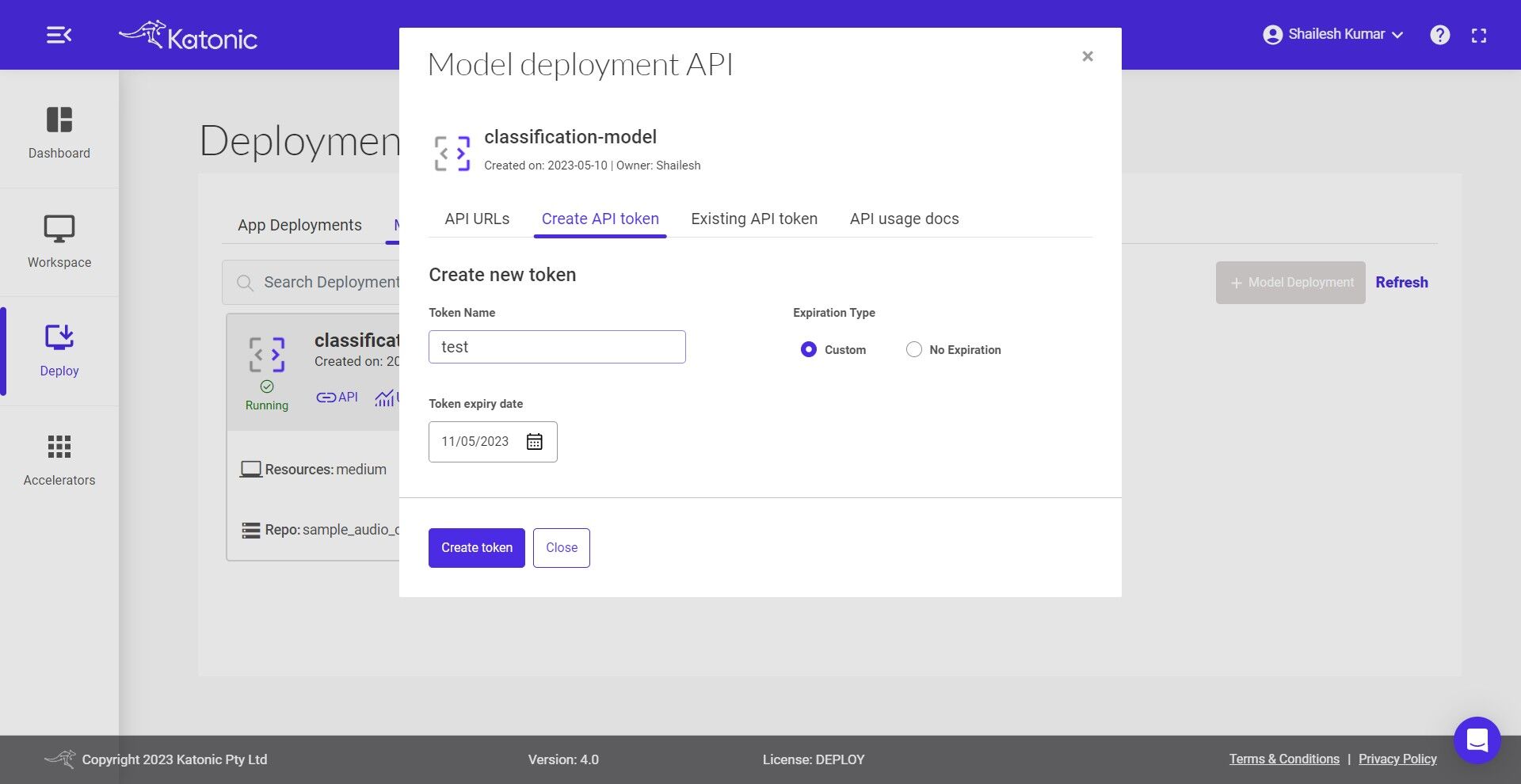
Select the Expiration Type
Set the Token Expiry Date
Click on Create Token and generate your API Token from the pop-up dialog box.
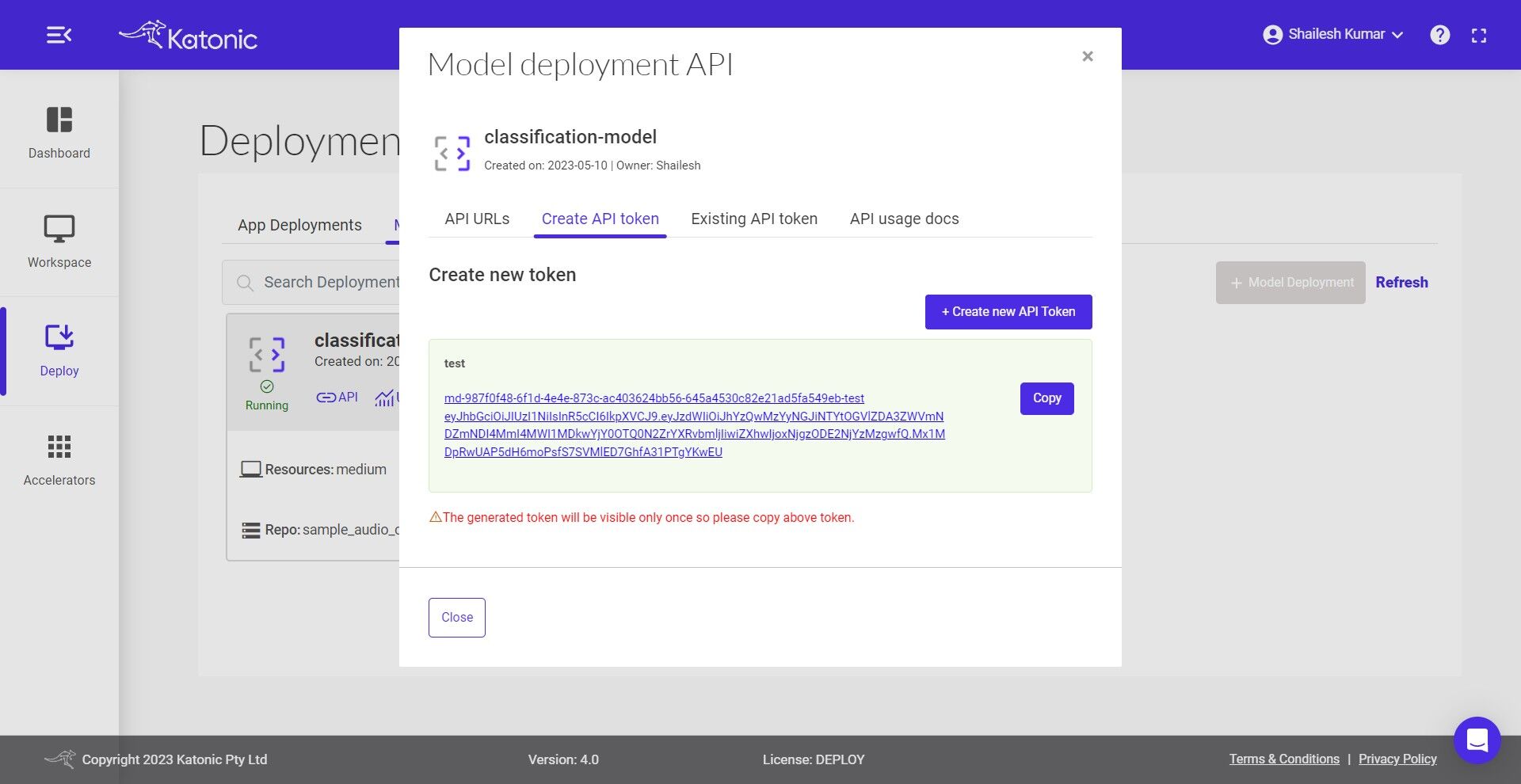
Note: A maximum of 10 tokens can be generated for a model. Copy the API Token that was created. As it is only available once, be sure to save it.
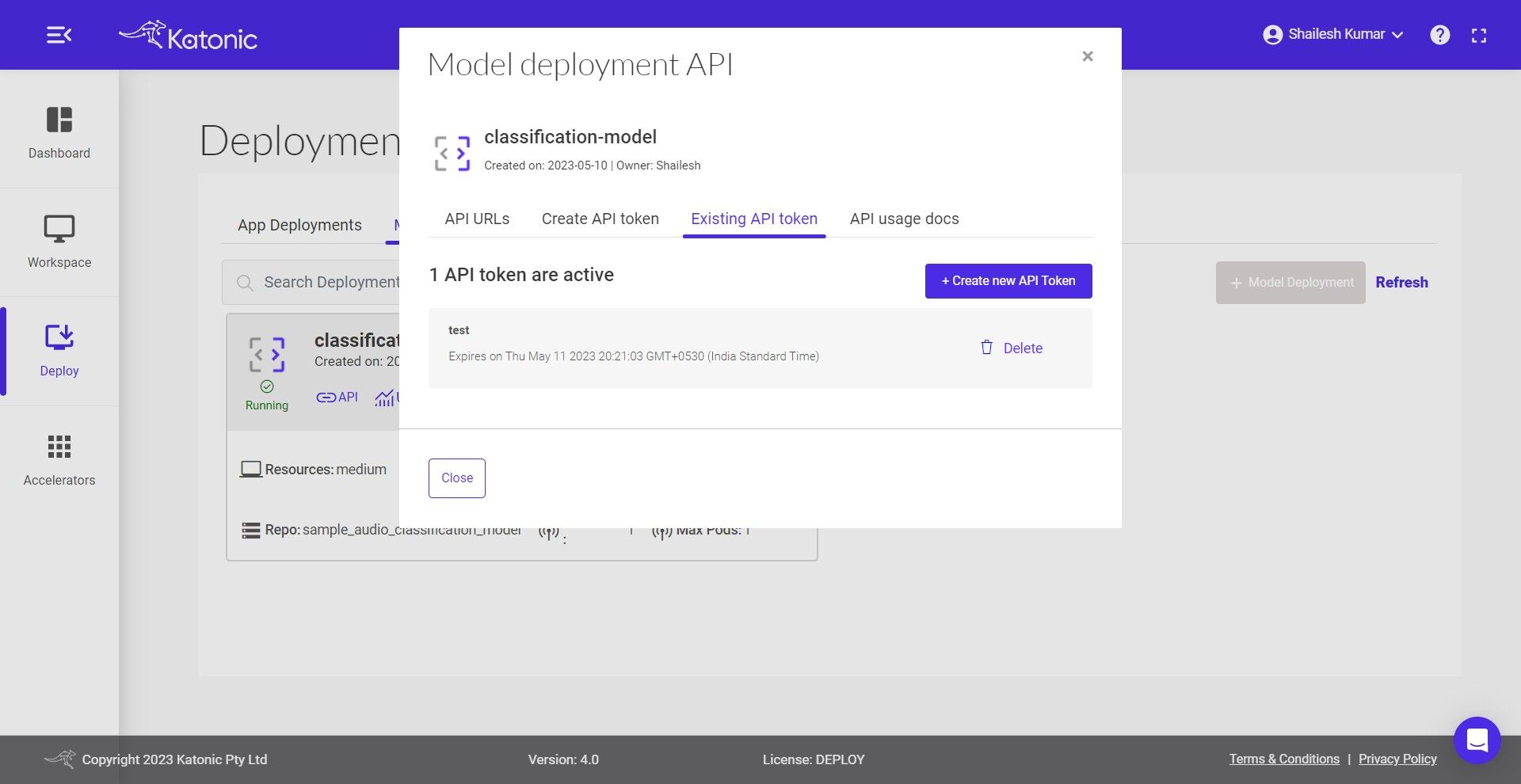
- Under the Existing API token section you can manage the generated token and can delete the no longer needed tokens.
- API usage docs briefs you on how to use the APIs and even gives the flexibility to conduct API testing.
- To know more about the usage of generated API you can follow the below steps:
- This is a guide on how to use the endpoint API. Here you can test the API with different inputs to check the working model.
- In order to test API you first need to Authorize yourself by adding the token as shown below. Click on Authorize and close the pop-up.
- Once it is authorise you can click on Predict_Endpoint bar and scroll down to Try it out.
- If you click on the Try it out button, the Request body panel will be available for editing. Put some input values for testing and the number of values/features in a record must be equal to the features you used while training the model.
- If you click on execute, you would be able to see the prediction results at the end. If there are any errors you can go back to the model card and check the error logs for further investigation.
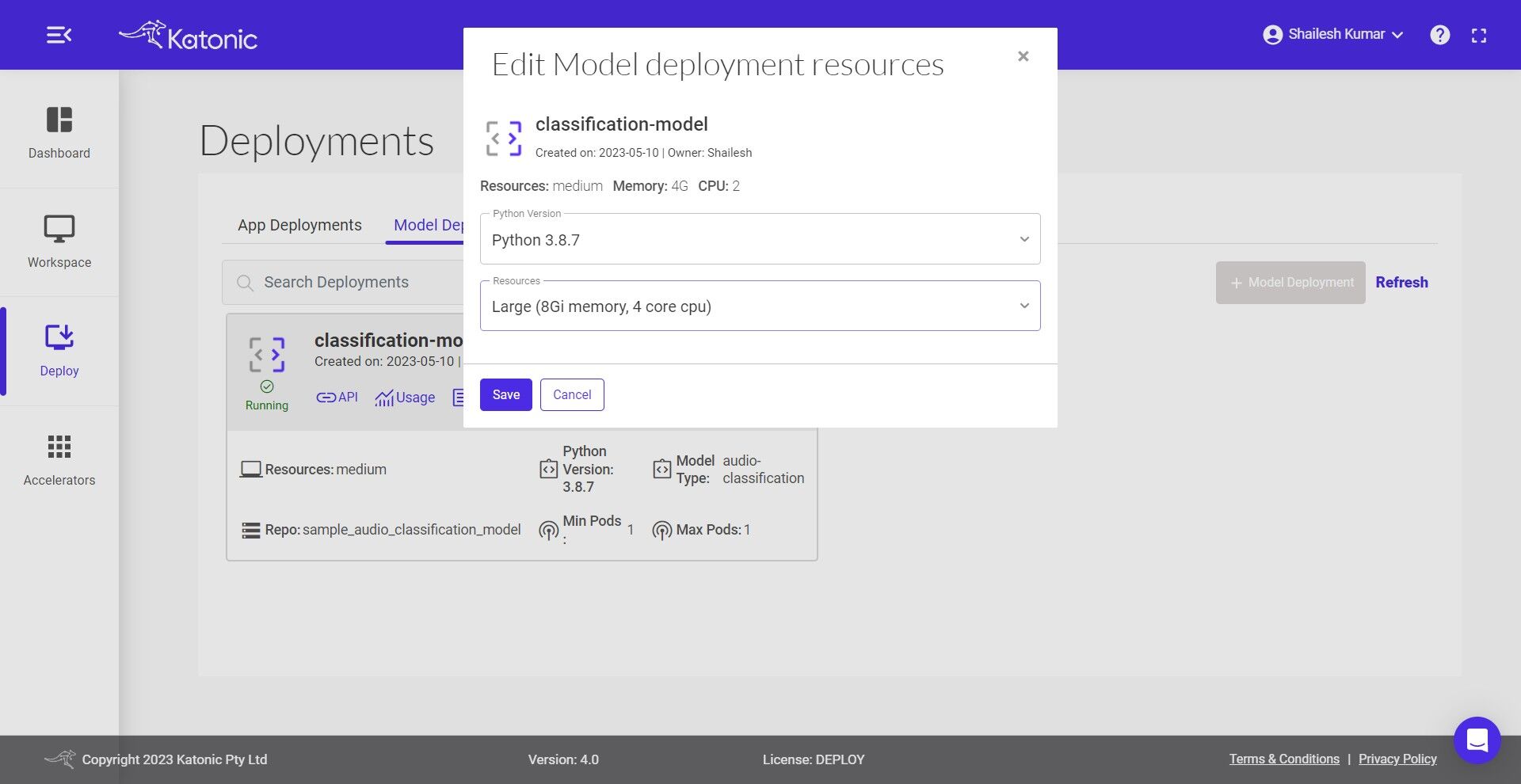
8.You can also modify the resources, version and minimum & maximum pods of your deployed model by clicking the Edit option and saving the updated configuration.
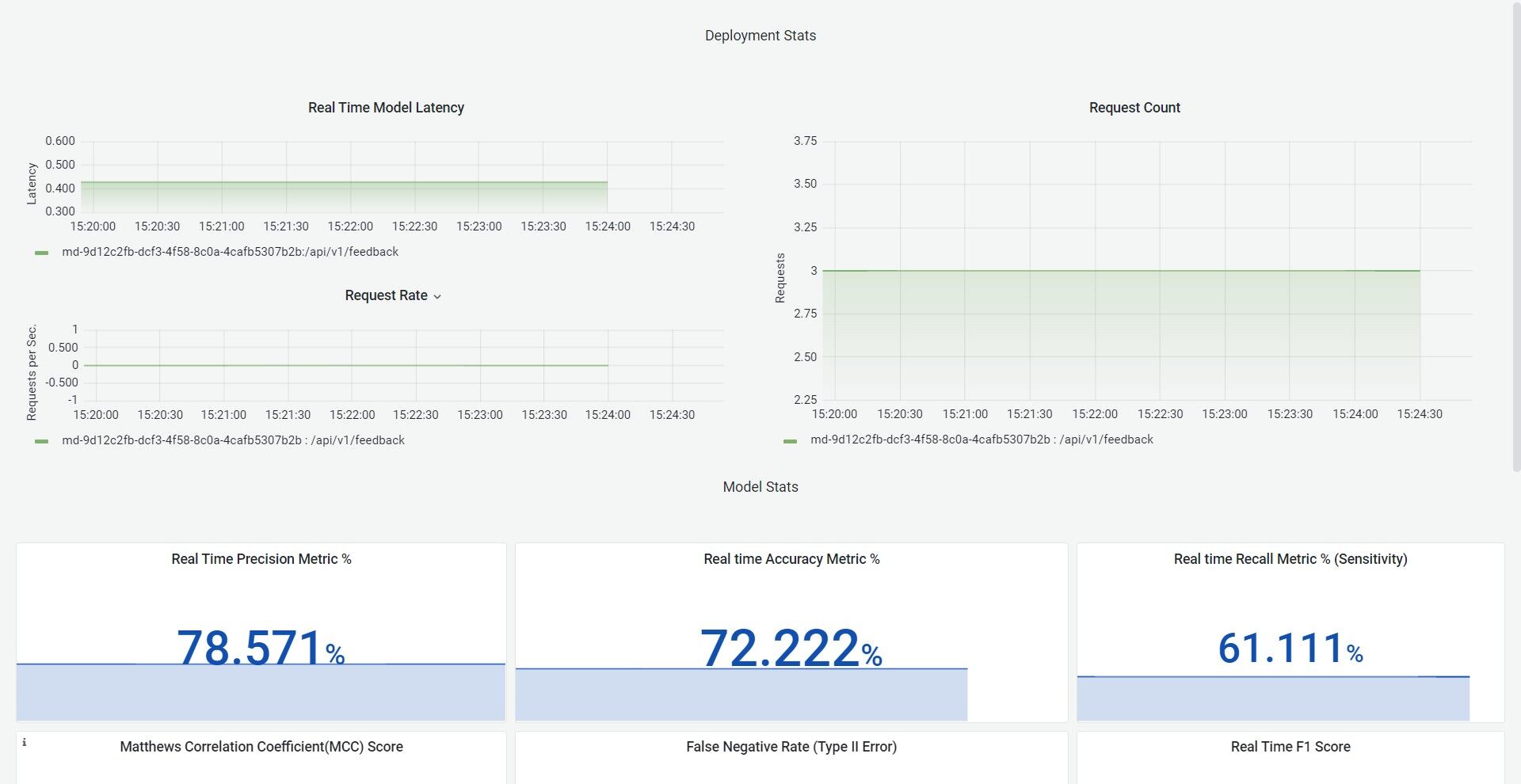
9.Click on Monitoring, and a dashboard would open up in a new tab. This will help to monitor the effectiveness and efficiency of your deployed model. Refer the Model Monitoring section in the Documentation to know more about the metrics that are been monitored.
10.To delete the unused models use the Delete button.